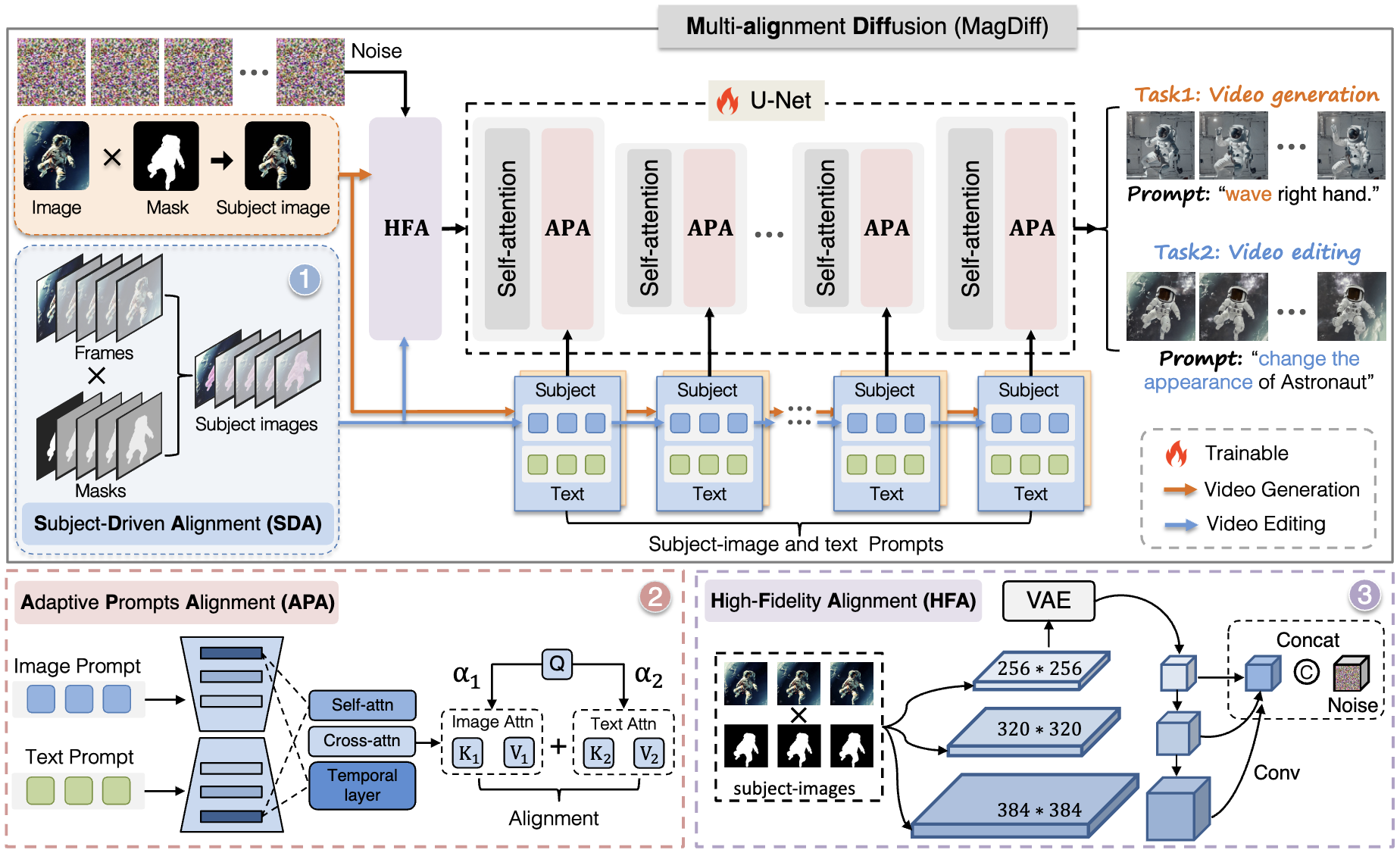
The diffusion model is widely leveraged for either video generation or video editing. As each field has its task-specific problems, it is difficult to merely develop a single diffusion for completing both tasks simultaneously. Video diffusion sorely relying on the text prompt can be adapted to unify the two tasks. However, it lacks a high capability of aligning heterogeneous modalities between text and image, leading to various misalignment problems. In this work, we are the first to propose a unified Multi-alignment Diffusion, dubbed as MagDiff, for both tasks of high-fidelity video generation and editing. The proposed MagDiff introduces three types of alignments, including subject-driven alignment, adaptive prompts alignment, and high-fidelity alignment. Particularly, the subject-driven alignment is put forward to trade off the image and text prompts, serving as a unified foundation generative model for both tasks. The adaptive prompts alignment is introduced to emphasize different strengths of homogeneous and heterogeneous alignments by assigning different values of weights to the image and the text prompts. The high-fidelity alignment is developed to further enhance the fidelity of both video generation and editing by taking the subject image as an additional model input. Experimental results on four benchmarks suggest that our method outperforms the previous method on each task.